Original face image
In this part, we'll take x and y partial derivatives of images by convolving them with the finite difference filters Dx and Dy.
First, I implemented 2D convolution operations using both four-loop and two-loop approaches with zero-padding support. I compared these implementations against scipy.signal.convolve2d to ensure correctness.
Applied a 9×9 box filter to demonstrate equivalence across all three implementations:



The four-loop implementation had the slowest runtime due to the nested loops, while the two-loop implementation had a moderate speedup because the kernel size was indexed instead of being iterated over. However, signal.scipy.convolve2d had the fastest runtime overall since it is optimized C code. All implementations used zero-padding to handle boundaries, specifically mode='same', boundary='fill', fillvalue=0 for the scipy function. The image is padded with zeros by (Kh//2, Kw//2) on all sides, ensuring the output maintains the same dimensions as the input image while properly handling edge pixels.
Applied finite difference operators Dx and Dy for edge detection:


Here, I applied the finite difference operators to the image to demonstrate edge detection capabilities.





To create an edge detection image, we select a threshold τ and at each position evaluate whether the gradient magnitude is greater than τ. The result is a binary image where pixel value 1 corresponds to the presence of an edge and 0 to the absence of an edge. I tried a couple of thresholds (0.1, 0.2, 0.25, 0.3, 0.4) and 0.35 provided the best balance between finding edges and removing noise. For example, the threshold of 0.2 had more noise (many specs in the background of the grass) and the threshold of 0.4 took away too many edges to properly show the man's figure.
First, I created a gaussian filter using cv2.getGaussianKernel() with a sigma value of 0.5 and n = int(2*np.ceil(3*sigma) + 1). To make it 2D, I took the outer product of this 1D gaussian with its transpose. Then, I convolved the image with the gaussian to smoothen it before taking its x and y partial derivatives like before, getting the gradient magnitude image, and the edge image with a lower threshold than before (0.2 showed the best results). This is compared to the same thing with a single convolution of the gaussian and Dx/Dy (called the derivative of the gaussian), and generating the respective images for comparison.






vs.


Results are identical due to associativity of convolution!



Convolution with linear filters is commutative and associative, so convolving I and G, then convolving this with Dx is the same as convolving I with G * Dx. Additionally, compared to the previous section, smoothing the image allows the result to have less white noise and the edges remain preserved.

Unsharp masking is a technique that starts off by blurring the original image using a low-pass filter (Gaussian in this case). This blurred image is subtracted from the original image to get the high-frequency components of the image, which correspond to the edges and fine details. Then, this high-frequency information is added back to the original image (by some scaling factor) which increases the edge contrast and makes them appear sharper and more defined. Below, the Taj Mahal is sharpened with varying scaling factors which impacts how pronounced the edges look. Let I denote a given grayscale 2D image, α denote the sharpening parameter, and G denote a gaussian filter.




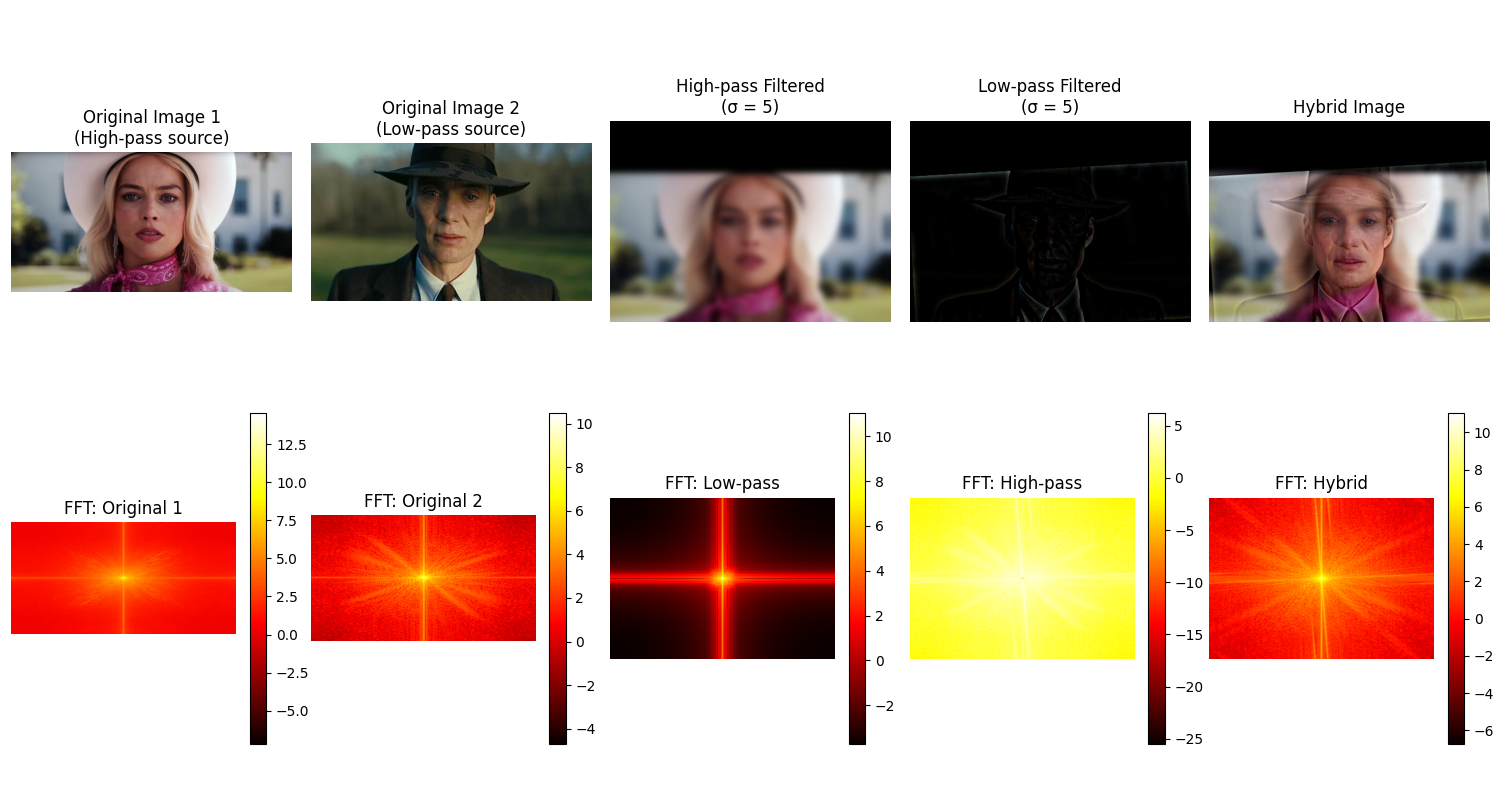
Using the hybrid images approach from the SIGGRAPH 2006 paper, I made static images that change in interpretation as a function of the viewing distance. When viewing these images from a close distance, the high frequency portion of one image is visible and viewing it from afar shows the low frequency portion of the other image.


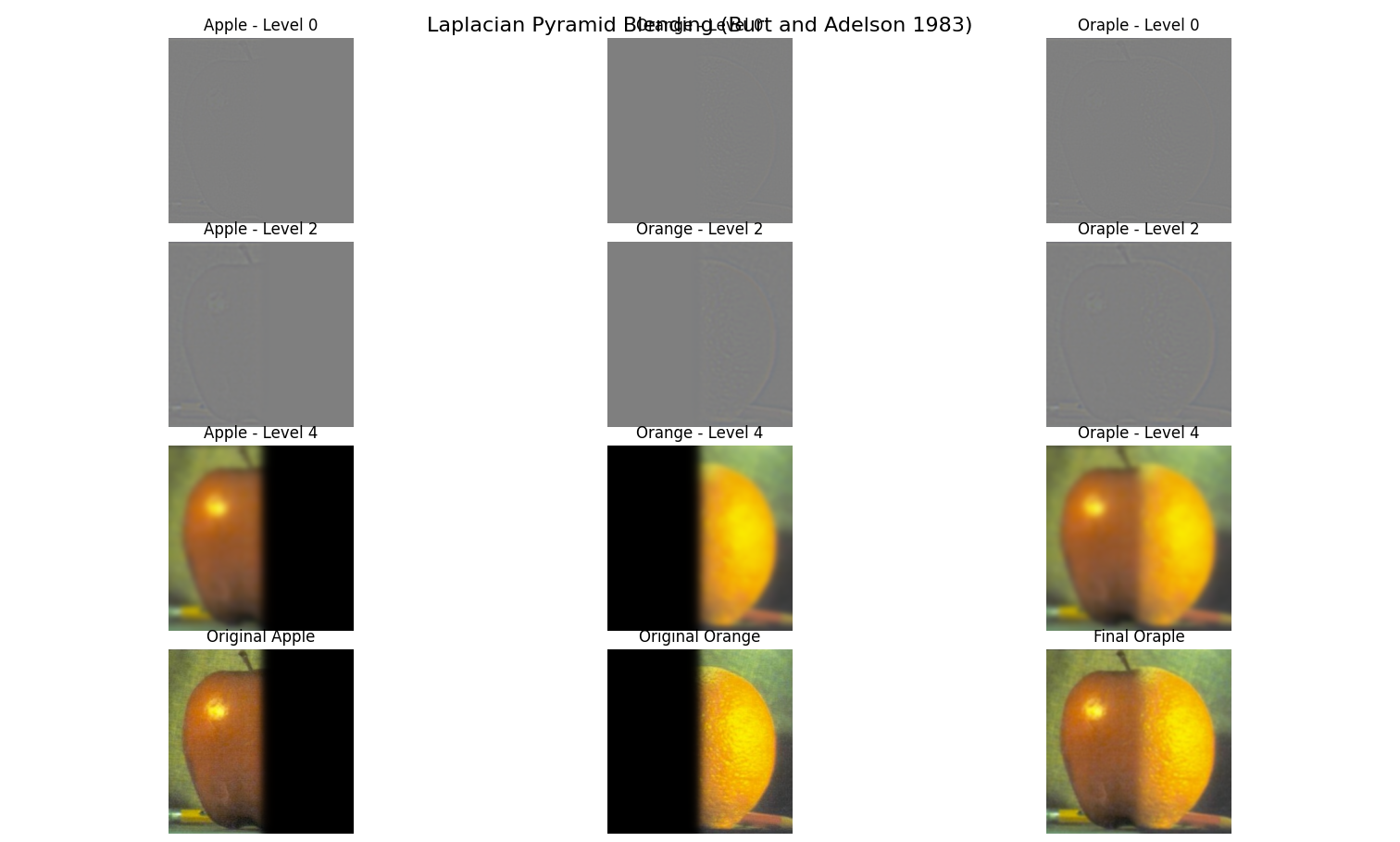
I implemented Gaussian and Laplacian stacks (without downsampling) in preparation for multiresolution blending. Unlike pyramids, stacks maintain the original image dimensions at each level, by applying the Gaussian filter at each level without subsampling.